엑셀을 보통 덧셈, 뺄셈, 곱셈, 나눗셈 정도의 기능만 가능하다고 아는 사람들이 많다.
조금 더 심화하면 숫자를 세는 Count 라던지, 평균을 내는 Average 등
누구나 손으로 할 수 있는걸 조금 더 빨리 해주는 기능 정도로 치부하는 것이다.
하지만 엑셀도 엄연히 개발자 툴 중 하나이다.
웬만한 통계 그리고 코딩까지도 가능하다!
오늘은 두 범위값들의 상관계수를 구할 수 있는 CORREL 함수에 대해서 알아보겠다.
엑셀 CORREL 함수
엑셀 CORREL 함수는 두 범위의 상관계수를 구하는 함수이다.
CORREL은 Correlative, 상관관계가 있는 것이라는 영어 단어를 의미한다.
범위는 반드시 숫자여야 하고 텍스트나 문자는 인식하지 못한다.
두 범위 모두 숫자여야 한다.
이 상관관계를 -1과 1사이의 값으로 계산해준다.
두 범위의 상관관계가 0 초과인 양수가 나오면 양의 상관관계가 있다고 말하고,
반대로 0 미만인 음수가 나오면 음의 상관관계가 있다고 말한다.
양의 상관관계는 어느 한 범위가 증가하면 다른 한 범위도 같이 증가한다는 것을 의미하고,
음의 상관관계는 어느 한 범위가 증가하면 다른 한 범위는 반대로 감소하는 것을 의미한다.
숫자가 클수록 상관관계가 더 크다.
1에 가까우면 아주 강한 양의 상관관계에 있다고 볼 수 있다는 것
또한 숫자가 조금이라도 양수 또는 음수로 치우쳐졌다고 해서 상관관계가 꼭 있다고 말하긴 어렵다.
양의 상관관계를 기준으로 0 ~ 0.2 정도는 상관관계가 없다고 봐도 무방하다.
일반적으로 0.5는 넘어야 상관관계가 있다고 말할 수 있다.
수치별 상관관계 정도는 아래 기준으로 볼 수 있다.
| 상관계수 | 상관관계 정도 |
| | 0.9 ~ 1.0 | | 매우 강한 상관관계 |
| | 0.7 ~ 0.9 | | 강한 상관관계 |
| | 0.4 ~ 0.7 | | 상관관계가 어느정도 있음 |
| | 0.2 ~ 0.4 | | 약한 상관관계 |
| | 0 ~ 0.2 | | 상관관계 없음 |
=CORREL(첫 번째 범위, 두 번째 범위)
=CORREL(array1, array2)
따로 인수 설명이 필요 없을 정도로 간단하고 직관적이다.
두 범위의 상관계수를 구하는 함수이니 두 범위를 각각 입력해주면 된다.
간단한 예제
아래 커피 메뉴들의 월별 판매량 데이터이다.
어디서 가져온 데이터가 아니라 내가 임의로 숫자를 막 넣은 데이터임을 참고해주길 바란다.
1~6월 동안의 커피 메뉴별 판매량 실적 데이터이다.
FORECAST 함수 예제를 그대로 활용해보았다.
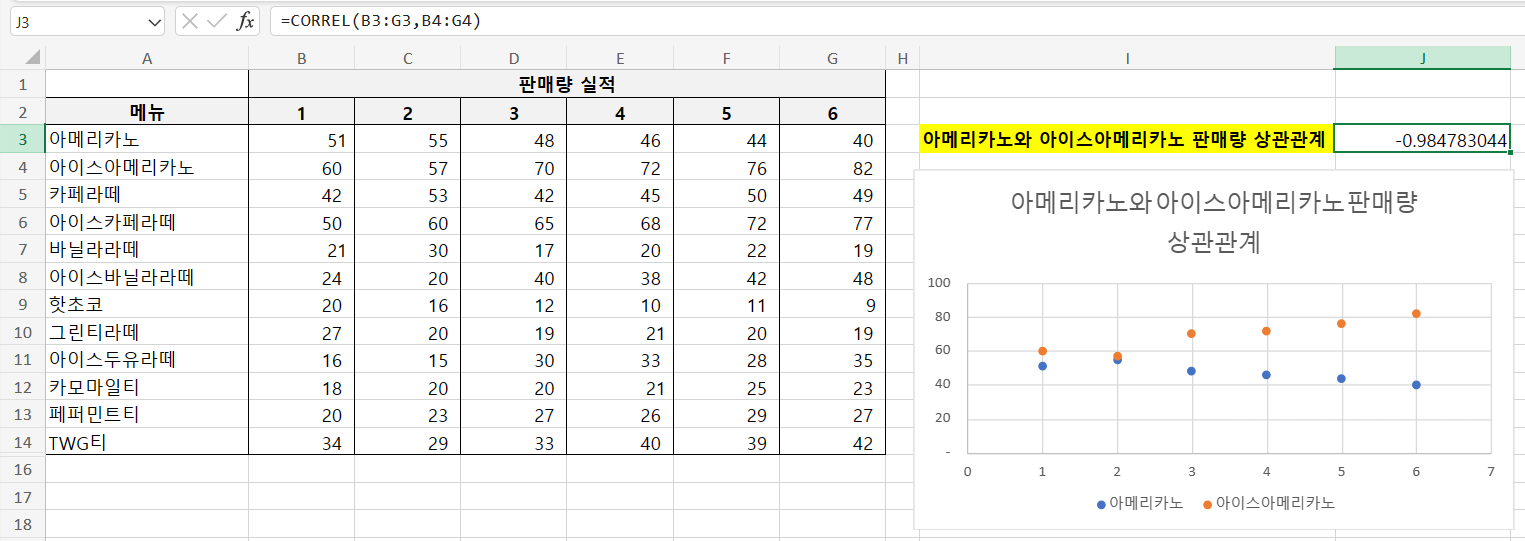
아메리카노와 아이스아메리카노 월별 판매량 간의 상관관계가 있을까?
내가 만든 데이터이기 때문에 단순히 의도적으로 날씨가 더워질수록 아메리카노는 판매량이 조금씩 줄고,
반대로 아이스아메리카노는 판매량이 조금씩 늘어난다고 가정하고 숫자를 넣었다.
=CORREL(B3:G3, B4:G4)
그렇게 했더니 두 커피의 판매량 상관관계는 "-0.984783044" 가 나왔다.
엄청난 음의 상관관계가 있다는 것을 의미한다.
분산형 그래프로 봤을 때도 증가폭과 감소폭이 굉장히 일정하게 나오는 것을 알 수 있다.
반대로 아메리카노와 카페라떼의 상관관계를 보자
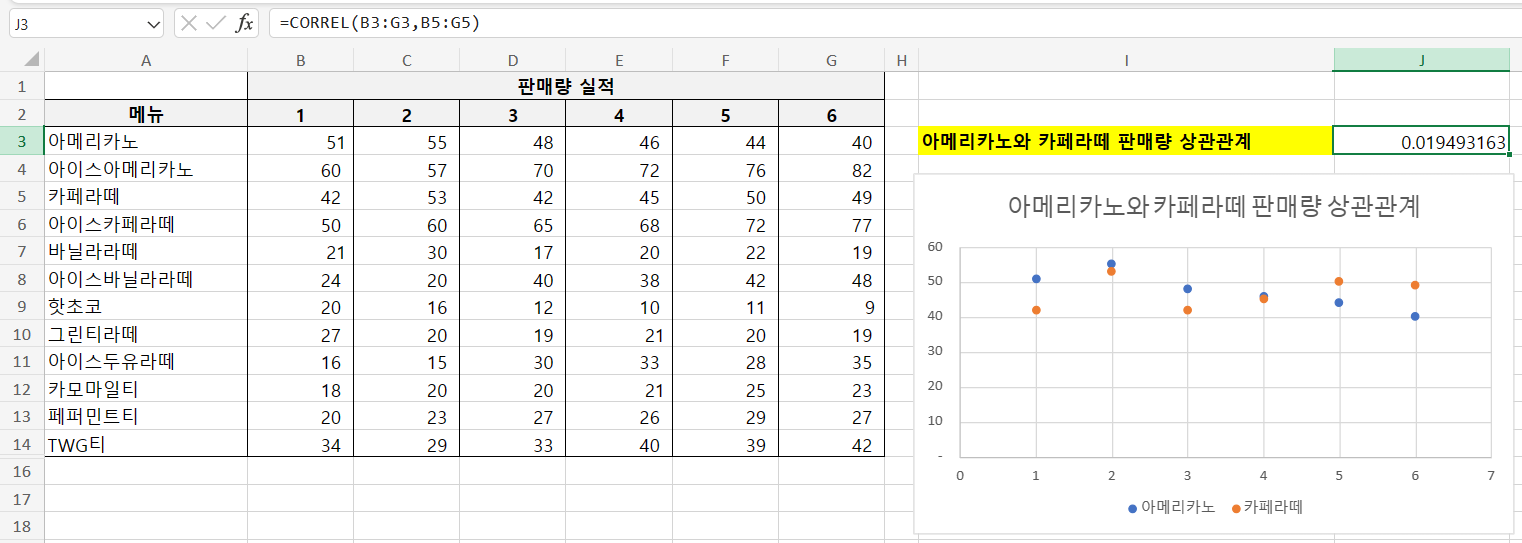
아메리카노와 카페라떼는 상관관계가 "0.019493163"으로 양의 상관관계긴 하지만 거의 관계가 없다고 봐도 무방하다.
분산형 그래프를 보더라도 같이 늘어나고 줄어드는 것 같다가도 또 반대로 늘어날 때 줄어들고 하는 걸 보면 관계가 없어보인다.
오류 유형
CORREL 함수는 두 숫자 범위의 상관계수를 구하는 함수인데 범위 간 개수가 동일해야 한다.
만약 두 범위의 개수가 다르다면 #N/A 오류를 반환한다.
그리고 범위 내의 값들이 모두 비어있거나 두 범위 중 하나의 범위라도 표준편차가 0이라면,
다시 말해 범위 내 모든 값들이 동일하다면 #DIV/0! 오류를 반환한다.
0으로 나눌 수 없다는 의미이기도 하다.
그리고 두 범위는 모두 숫자만 가능하다고 했지만,
범위 내에 텍스트, 논리값, 빈값 등이 들어가도 오류로 반환하진 않는다.
이 값들은 그냥 무시하고 상관계수를 구하게 된다.
두 범위의 데이터 개수가 다르면 오류를 반환하는데 개수는 같지만 범위 내에 텍스트, 논리값, 빈값 등 무시하는 값이 들어가는건 또 계산을 해준다.
또 값이 0이 들어가있는건 무시하지 않고 계산에 포함해준다.
오늘은 두 범위값의 상관계수를 구해주는 CORREL 함수에 대해 알아보았다.
아무리 그래프로 멋지게 그려놓아도 이게 상관관계가 있는건지, 있다면 얼마나 있는건지 판단하기는 어렵다.
데이터 분석을 해서 보고를 한다고 가정해도,
"그래프 내 두 집단의 점들 추세를 봤을 때 어느정도 상관관계가 있다고 볼 수 있습니다." 라고 말하는 것보다는,
"그래프 내 두 집단의 점들 간 상관관계는 0.87로 강한 양의 상관관계가 있습니다." 라고 말하는 것이 훨씬 설득력 있을 것이다.
함께보면 좋은 글
엑셀에서도 선형회귀를 활용하여 예측을 할 수 있을까? FORECAST.LINEAR 함수 알아보기
엑셀은 간단한 통계 기능만 가능할 것 같은데.. 혹시 선형회귀 같은 분석 기법을 활용하여 모델을 만들 수도 있을까? 놀랍지만 엑셀에서도 이런 기능이 있다. 엑셀에서도 선형회귀를 활용하여
ko-link-world.com
엑셀 순위 매기기 랭크 RANK RANK.AVG RANK.EQ 함수 사용방법과 차이점 알아보기!
엑셀에서 VLOOKUP이나 SUMIF 등 실무에서 자주 쓰이기로 유명한 함수에 비해서는 활용도가 떨어지긴 하지만, 그래도 유용하게 활용하고 있는 함수가 바로 RANK 함수이다. 점수별로 순위를 빠르게 내
ko-link-world.com
'Excel 함수' 카테고리의 다른 글
| 복리의 마법, 엑셀로 어떻게 계산하면 좋을까? FV 함수로 미래가치 계산하는 방법! (2) | 2024.01.14 |
|---|---|
| 데이터 기초 통계 분석도 엑셀에서! AGGREGATE 함수 사용 방법 알아보기 (1) | 2024.01.09 |
| 엑셀 LEFT, RIGHT, MID 함수로 원하는 텍스트 추출하거나 제거하는 방법 (32) | 2024.01.06 |
| 엑셀 조건에 맞는 평균 구하기, AVERAGEIF 함수 사용 방법 (28) | 2024.01.05 |
| 엑셀에서도 선형회귀를 활용하여 예측을 할 수 있을까? FORECAST.LINEAR 함수 알아보기 (24) | 2024.01.04 |



